
AI-Powered Audio Recognition Platform
A full-stack web application that classifies audio in real time as voice or sound effects using dual AI models running in parallel. The system combines OpenAI Whisper for speech-to-text with an AudioSet classifier for sound identification, automatically selecting the best result through confidence-based scoring. Users can upload files, record from a microphone, or pick from a curated sample library — all within a polished, responsive interface.
About the project
The Product: A full-stack web application for real-time audio recognition that classifies audio as either voice or sound effects using machine learning. The system runs two AI models in parallel — OpenAI Whisper for speech-to-text and AudioSet classifier for sound identification — and selects the best result based on confidence scoring.
What it Does: It provides an intuitive interface for audio analysis through three input methods: selecting from a library of sample audio files, uploading local audio files (MP3, WAV, M4A, FLAC up to 1 MB), and recording directly from the browser microphone (up to 2 minutes). The application then classifies the input as voice or sound effect and displays the result with a custom audio player.
How it Works: Built on a modern full-stack architecture (Python/FastAPI + Next.js/React), the system uses a Dual-Model Inference Engine. When audio is submitted, the backend processes it through two models concurrently using a thread pool. OpenAI Whisper transcribes speech and calculates a confidence score, while the AudioSet classifier converts audio to 16 kHz mono WAV, extracts features, and returns the top 5 predicted sound labels. A confidence-based selection algorithm determines the final result — if Whisper confidence is 0.7 or higher the result is treated as voice; if below 0.05 the classifier result is used as a sound effect.
The Advantage: ML models are lazy-loaded at server startup, eliminating cold-start delays for individual requests. Audio format conversion is handled transparently by FFmpeg. The system automatically detects Apple Silicon MPS acceleration and falls back to CPU when unavailable, ensuring consistent performance across different hardware environments.
Learn tech information for this project
About the project
The Product: A full-stack web application for real-time audio recognition that classifies audio as either voice or sound effects using machine learning. The system runs two AI models in parallel — OpenAI Whisper for speech-to-text and AudioSet classifier for sound identification — and selects the best result based on confidence scoring.
What it Does: It provides an intuitive interface for audio analysis through three input methods: selecting from a library of sample audio files, uploading local audio files (MP3, WAV, M4A, FLAC up to 1 MB), and recording directly from the browser microphone (up to 2 minutes). The application then classifies the input as voice or sound effect and displays the result with a custom audio player.
How it Works: Built on a modern full-stack architecture (Python/FastAPI + Next.js/React), the system uses a Dual-Model Inference Engine. When audio is submitted, the backend processes it through two models concurrently using a thread pool. OpenAI Whisper transcribes speech and calculates a confidence score, while the AudioSet classifier converts audio to 16 kHz mono WAV, extracts features, and returns the top 5 predicted sound labels. A confidence-based selection algorithm determines the final result — if Whisper confidence is 0.7 or higher the result is treated as voice; if below 0.05 the classifier result is used as a sound effect.
The Advantage: ML models are lazy-loaded at server startup, eliminating cold-start delays for individual requests. Audio format conversion is handled transparently by FFmpeg. The system automatically detects Apple Silicon MPS acceleration and falls back to CPU when unavailable, ensuring consistent performance across different hardware environments.
Learn tech information for this project

AI-Powered Audio Recognition Platform
Dual-model AI system that classifies audio as voice or sound effects in real time using parallel inference.
AI-Powered Audio Recognition Platform
Dual-model AI system that classifies audio as voice or sound effects in real time using parallel inference.
Features
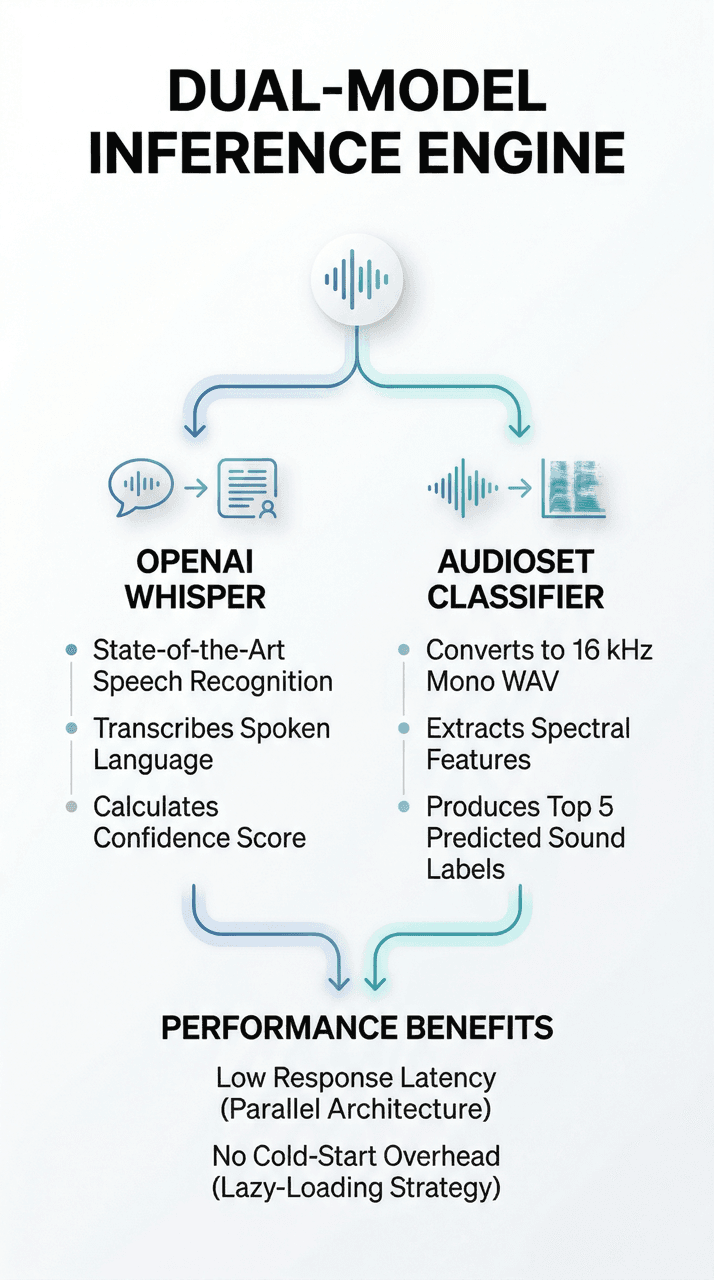
Dual-Model Inference
At the heart of the platform lies a dual-model inference engine that processes every audio sample through two specialized AI pipelines simultaneously. OpenAI Whisper — a state-of-the-art speech recognition model — transcribes spoken language and calculates a confidence score reflecting the probability that the input contains human speech. In parallel, an AudioSet classifier converts the raw audio to a standardized 16 kHz mono WAV format, extracts spectral features, and produces the top five predicted sound labels ranked by confidence.
A Python-based thread pool executor orchestrates both models concurrently, ensuring the total inference time is determined by the slower model rather than the sum of both. This parallel architecture keeps response latency low even under sustained load, and the lazy-loading strategy defers heavy model initialization to server startup so that individual requests are never blocked by cold-start overhead.
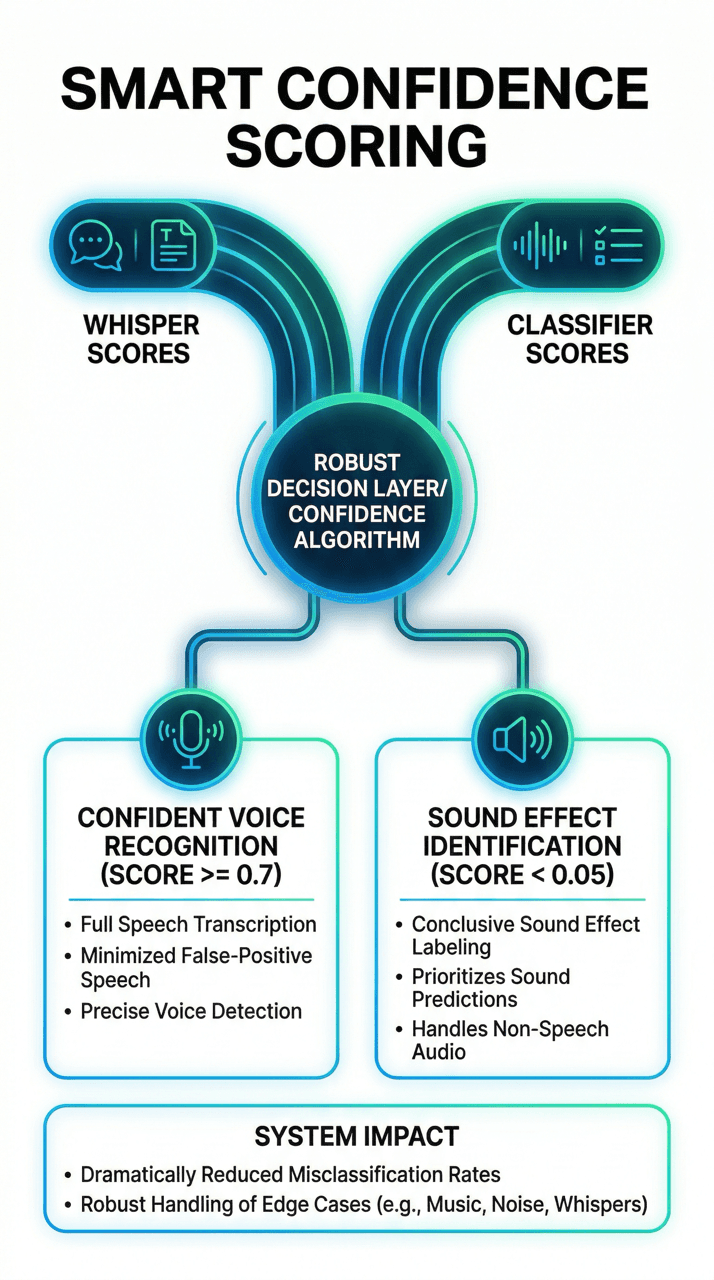
Smart Confidence Scoring
Raw model outputs alone are insufficient for reliable classification — a robust decision layer is essential. The platform implements a confidence-based selection algorithm that compares scores from both models and applies a set of carefully tuned thresholds. When Whisper reports confidence of 0.7 or higher and that score exceeds the classifier's top prediction, the system returns the result as recognized voice along with the full transcription text.
When Whisper confidence falls below 0.05, the platform conclusively identifies the input as a sound effect and returns the classifier's top label. For scores between these thresholds, the classifier result takes priority, minimizing false-positive speech detections. This layered decision logic dramatically reduces misclassification rates compared to single-model approaches, particularly for edge-case audio like whispered speech, musical instruments, or heavily distorted recordings.
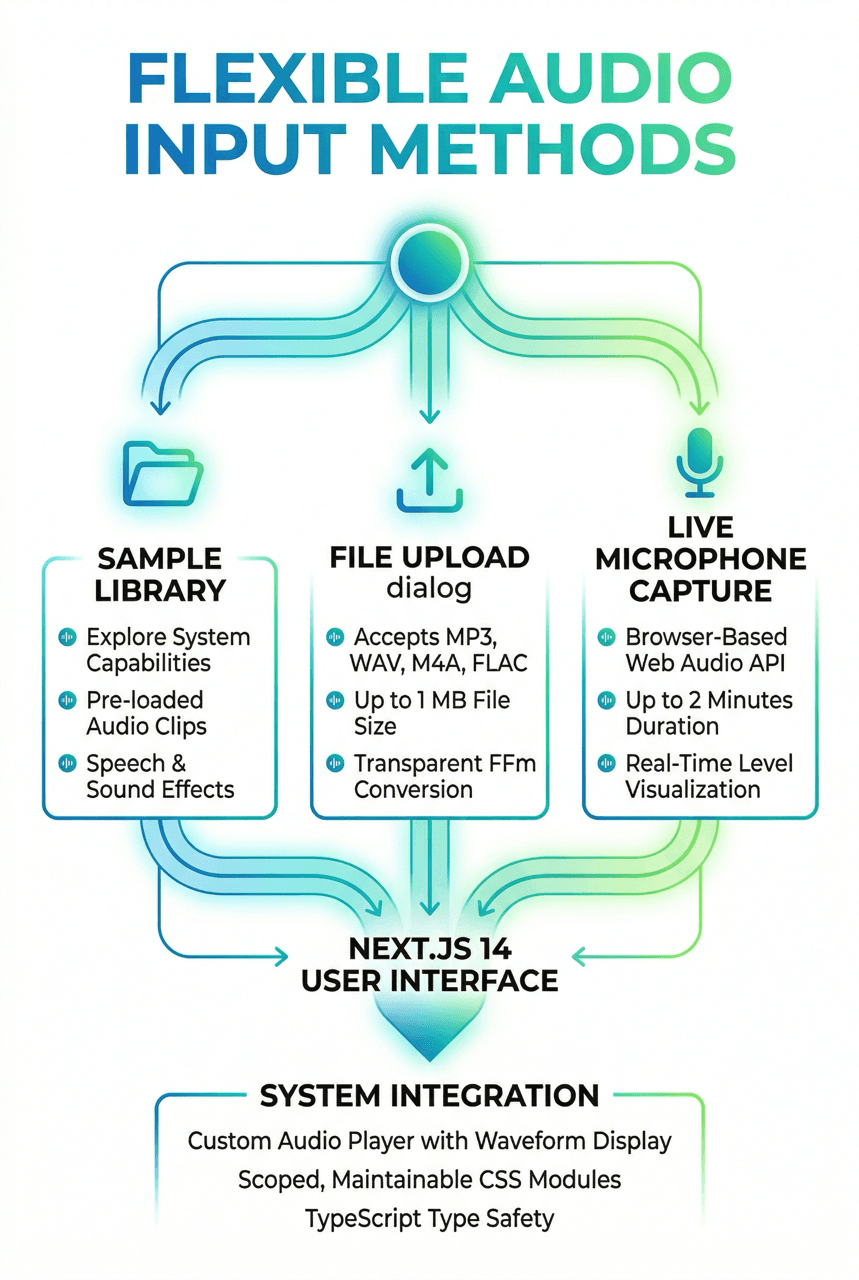
Flexible Audio Input
The application provides three intuitive input methods designed to cover every user scenario. A curated sample library lets users explore the system's capabilities with pre-loaded audio clips spanning both speech and sound effects. A file upload dialog accepts MP3, WAV, M4A, and FLAC formats up to 1 MB, with server-side format conversion handled transparently by FFmpeg. For live capture, the browser-based microphone recorder — built on the Web Audio API — supports recordings of up to two minutes with real-time level visualization.
The Next.js 14 frontend renders a polished, responsive interface with a custom audio player that provides playback controls, waveform display, and clear labeling of the result type (voice or sound effect). CSS Modules ensure scoped, maintainable styles, while TypeScript enforces type safety across all components. Together, these input methods and UI elements create a seamless experience that invites exploration and requires zero technical knowledge from the end user.
Features
Dual-Model Inference
At the heart of the platform lies a dual-model inference engine that processes every audio sample through two specialized AI pipelines simultaneously. OpenAI Whisper — a state-of-the-art speech recognition model — transcribes spoken language and calculates a confidence score reflecting the probability that the input contains human speech. In parallel, an AudioSet classifier converts the raw audio to a standardized 16 kHz mono WAV format, extracts spectral features, and produces the top five predicted sound labels ranked by confidence.
A Python-based thread pool executor orchestrates both models concurrently, ensuring the total inference time is determined by the slower model rather than the sum of both. This parallel architecture keeps response latency low even under sustained load, and the lazy-loading strategy defers heavy model initialization to server startup so that individual requests are never blocked by cold-start overhead.
Smart Confidence Scoring
Raw model outputs alone are insufficient for reliable classification — a robust decision layer is essential. The platform implements a confidence-based selection algorithm that compares scores from both models and applies a set of carefully tuned thresholds. When Whisper reports confidence of 0.7 or higher and that score exceeds the classifier's top prediction, the system returns the result as recognized voice along with the full transcription text.
When Whisper confidence falls below 0.05, the platform conclusively identifies the input as a sound effect and returns the classifier's top label. For scores between these thresholds, the classifier result takes priority, minimizing false-positive speech detections. This layered decision logic dramatically reduces misclassification rates compared to single-model approaches, particularly for edge-case audio like whispered speech, musical instruments, or heavily distorted recordings.
Flexible Audio Input
The application provides three intuitive input methods designed to cover every user scenario. A curated sample library lets users explore the system's capabilities with pre-loaded audio clips spanning both speech and sound effects. A file upload dialog accepts MP3, WAV, M4A, and FLAC formats up to 1 MB, with server-side format conversion handled transparently by FFmpeg. For live capture, the browser-based microphone recorder — built on the Web Audio API — supports recordings of up to two minutes with real-time level visualization.
The Next.js 14 frontend renders a polished, responsive interface with a custom audio player that provides playback controls, waveform display, and clear labeling of the result type (voice or sound effect). CSS Modules ensure scoped, maintainable styles, while TypeScript enforces type safety across all components. Together, these input methods and UI elements create a seamless experience that invites exploration and requires zero technical knowledge from the end user.
Contact Us






Anastasia Timoshenko
Regional Account Manager
1000+
Delivered projects
300+
Clients worldwide
700+
In-house developers
28+
Years in industry